Predicting Ratings of Movies-Based-on-Books by their Books
by Kenneth Myers
As the third week at Metis comes to a close I finally find myself with some free time. The second project required most of my attention and between class, the project, and challenges 2-4 I found myself often working 12-16 hours a day. Fortunately the winter storm allowed me to stay focused last weekend.
The focus of my investigation was the relationship between movie ratings and ratings of the books they are based on. I came up with the idea from a post on FiveThirtyEight titled, The 20 Most Extreme Cases Of ‘The Book Was Better Than The Movie’. The article explores the relationship between book ratings by users on GoodReads and the aggregated critic ratings of corresponding movies on Metacritic. Despite a defense by the author, many readers criticized his choosing of movie critic ratings over general users. I decided to take a stab at examining this relationship while also trying to find a more complex regression with other variables (such as MPAA rating, runtime, and gross).
I began by applying many of the tools we recently learned. I used Beautiful Soup 4 to scrape IMDB and GoodReads (I also used GoodRead’s API to search for books). I then scraped MetaCritic (to compare my data to the original data) using Selenium (although they also have an API, I wanted to test what I learned). I successfully scraped MPAA ratings, runtimes, grosses, budgets, movie ratings, book ratings, and their respective counts.
I ended up scraping 500 top movies based on books from IMDB which was cut down to 350 when combined with the GoodReads data. I then sought a model to explain the effect of GR rating on the IMDB rating.
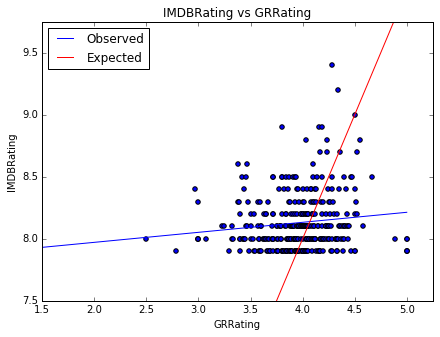
I found a weak relationship so I added more variables (runtime, MPAA rating, rating count and rating count^2) to find a better model. I cross validated various models (Lasso, Ridge, Linear Regression) in order to determine which was best for the data.
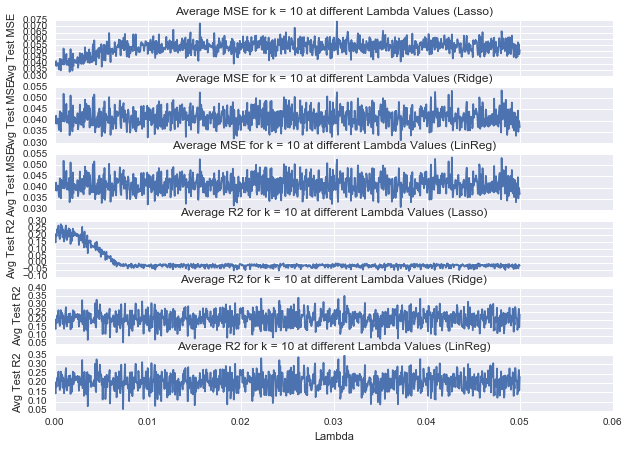
The MSE was worst for the Lasso model (even at low λ) and there wasn’t much difference between the Ridge and Linear Regression models. I decided to procede with a linear regression model.
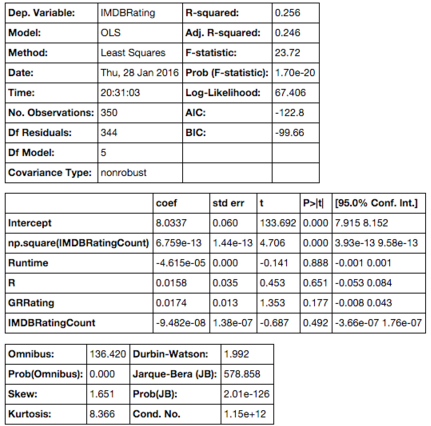
From here I found that the only variable of significance, the one with a p-value<0.05, was (rating count)^2. Unfortunately this doesn’t tell me much about predicting movie rating and it is also not surprising that movies with higher number of ratings (more popular) have higher ratings. So far I had found a relationship between ratings and rating counts, and that movie ratings were not strongly correlated with book ratings.
I restarted my analysis but this time using only data from the last 10 years so I could include movie gross and budget data. I had previously excluded this because IMDB’s released dates are a mess and written in any and every possible format making it difficult to adjust for inflation. Unfortunately, I found that there was an even worse relationship between movie and book ratings as shown by the figure below.
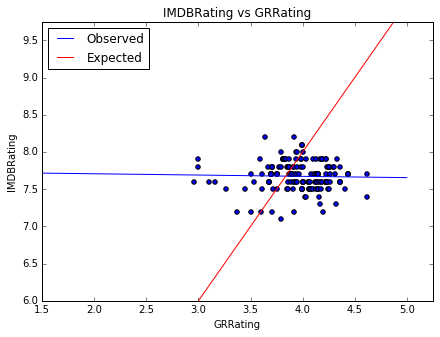
I again found a linear regression model to be the better model and tested a number of variables. This time I found that the significant variables were ratings count, budget, and runtime. Interestingly, of these variables runtime seems to have the largest effect on IMDB rating.
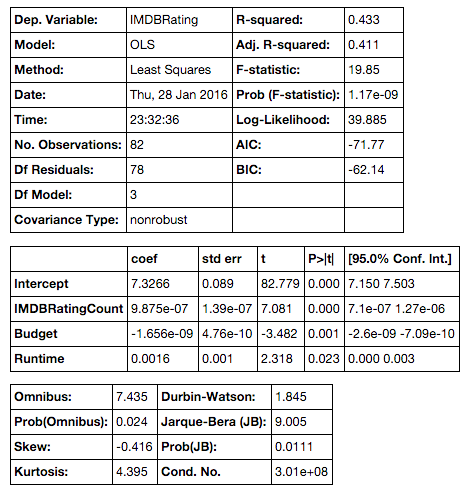
So once again I found that book ratings do not seem to have a strong effect on the movie adaptations’ ratings. Neither do movie gross nor MPAA ratings. On the other hand, runtimes, movie budgets, and the number of ratings for a movie seem to have an effect.
As an extra analysis I also examined the extreme cases where books were better than the movies and movies better than the books. Using IMDB ratings, I found completely different lists than FiveThirtyEight.
In the figures below, the top figure shows extreme cases where movies were rated better than their books, and the bottom figure shows extreme cases where the books were better than the movies. In both figures, FiveThirtyEight’s data is shown on the right.
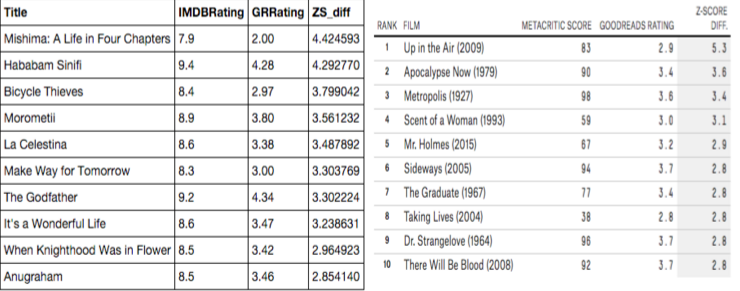
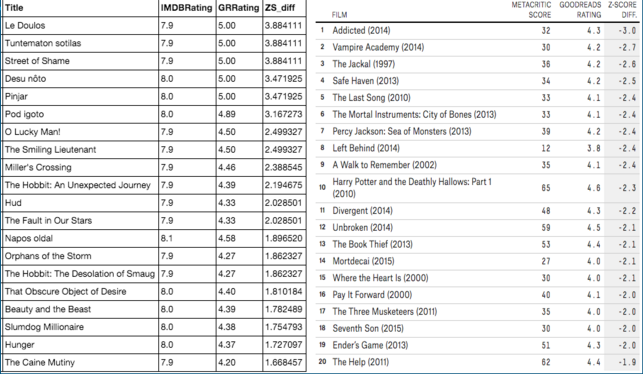
To learn more about this project check it out on Github or see my presentation.
Subscribe via RSS
{kind=link}